
Kun asiakirja skannataan (PDF) tai kuvapohjainen (JPEG/PNG), tietokone lukee sisällön pisteinä ja pikseleinä. Jotta tietokone tunnistaa sen sisällön merkkeinä, tarvitset OCR-työkalun muuntaaksesi sen koneellisesti luettavaksi tiedostoksi.
1. Lataa tiedostosi
Voit olla varma, että tiedostosi ladataan turvallisesti salatun yhteyden kautta. Tiedostot poistetaan pysyvästi käsittelyn jälkeen.
- Jos haluat ladata tiedostot tietokoneeltasi, napsauta”Lataa PDF-tiedosto”ja valitse tiedostot, joita haluat muokata tai vetää ja pudottaa tiedostot sivulle.
- Jos haluat ladata tiedostoja Dropboxista, Google Drivesta tai verkkosivustolta, jossa tiedostosi sijaitsevat, laajenna avattavaa luetteloa ja valitse tiedostosi.
- Voit ladata yhden tiedoston kerrallaan ilmaisia tilejä varten, sillä aikaaPäivitetyt tilitovat oikeutettuja lataamaan10 tiedostoa kerrallaan.

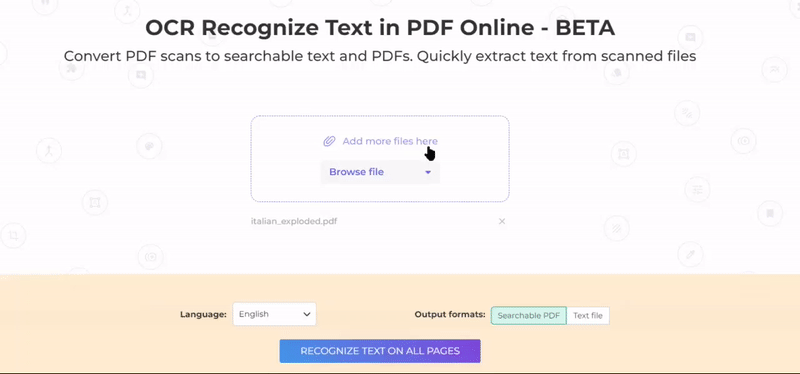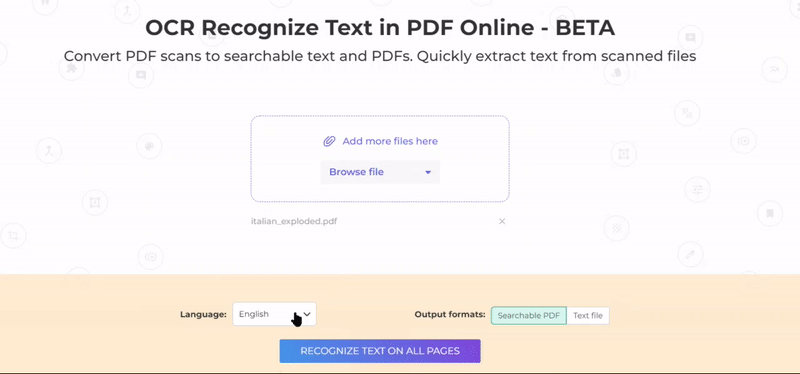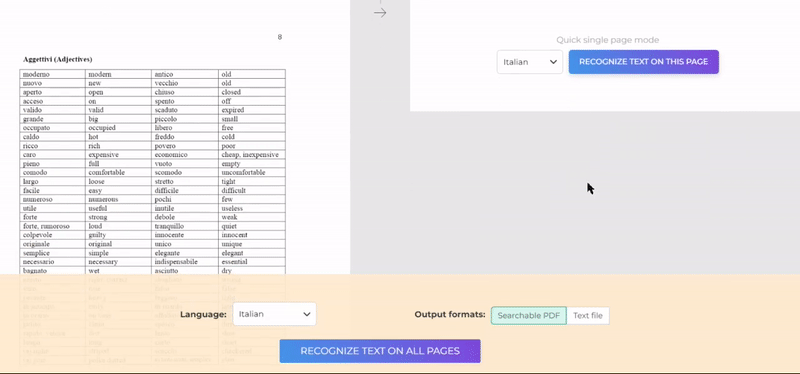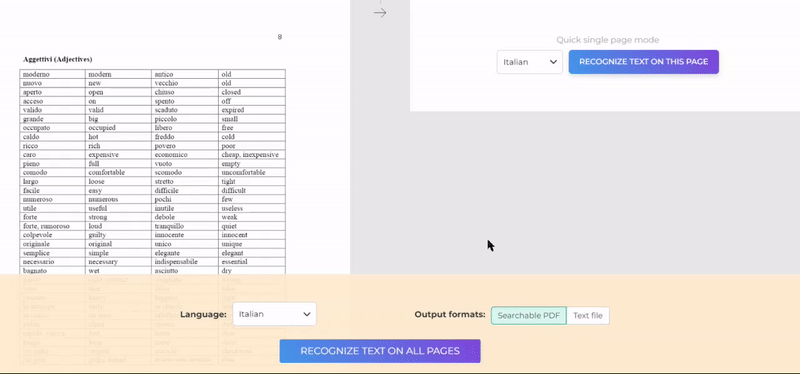
2. PDF-dokumentin kielen valinta
Valitse asiakirjan kieli, koska OCR-muunnos toimii parhaiten, kun se on määritetty. Kaikkien epäselvien sanojen ratkaiseminen olisi myös helpompaa kielen mukaan.
3. Valitse Tulostusmuoto ja Tallenna
Asiakirjojen muuntamiseen annetaan vaihtoehtoja -haettavissa PDF tai tavallinenteksti tiedosto joka purkaa tiedot.txt-tiedostosta. A haettavissa PDF is still a PDF file that contains content that can be recognized as characters.
Valitse haluamasi vaihtoehto ja napsauta”Tunnista teksti kaikilla sivuilla” aloittaa prosessin.
Kun prosessi on valmis, tallenna muunnettu tiedosto napsauttamalla”Lataa” tai voit myös ladata asiakirjat Google Drive- tai Dropbox-tileillesi.
OCR-prosessin tarkkuus
On suositeltavaa olla pakkaamatta asiakirjaa ennen OCR-prosessin suorittamista. Korkeamman resoluution asiakirjat antavat yleensä paremman tuloksen.
Valitettavasti tunnustetun tekstin 100% tarkkuus ei ole taattu, mutta tämä on paras lähestymistapa.
HUOMAUTUS: Työkalu toimii parhaiten, jos selaimen välimuisti tyhjennetään